Disaster Recovery é uma decisão de negócio executada pela engenharia.
No mês passado, discutimos os conceitos de RTO e RPO. Mas, na prática, como um Cloud Architect decide entre Pilot Light e Warm Standby? A resiliência não é mais sobre ter uma cópia dos dados, mas sobre a capacidade de execução do Data Plane e a automação via infraestrutura como código (IaC).
A figura abaixo resume a evolução das estratégias de Disaster Recovery na AWS, mostrando como custo, complexidade e tempo de recuperação aumentam conforme a criticidade da aplicação
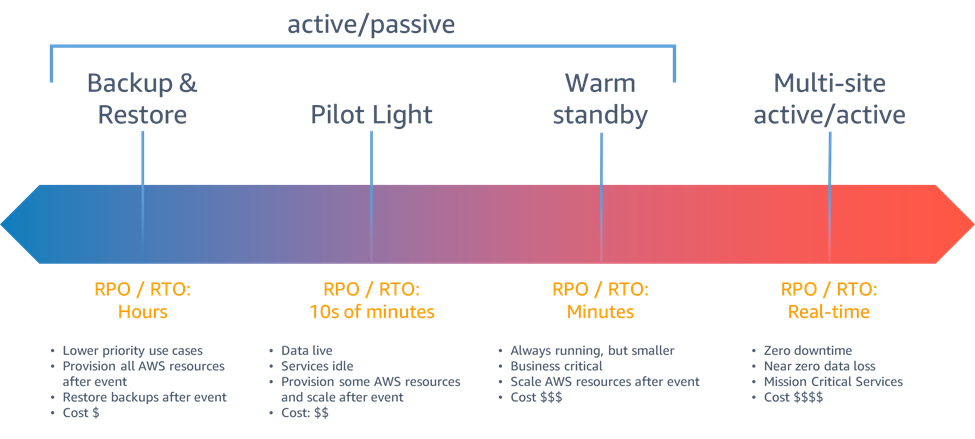
À medida que avançamos da esquerda para a direita no diagrama, reduzimos drasticamente o tempo de recuperação (RTO) e a perda de dados aceitável (RPO), porém aumentamos o custo operacional e a complexidade da arquitetura.
A Decisão Técnica: Onde investir seu orçamento de DR?
Escolher a estratégia correta exige equilibrar o impacto financeiro da inatividade versus o custo de manter recursos ociosos. Abaixo, detalhamos os componentes críticos que definem cada nível de maturidade:
1. Backup e Restore: O papel fundamental do IaC
Diferente do que muitos pensam, o Backup & Restore não é manual. Para atingir um RTO aceitável, é obrigatório o uso de AWS CloudFormation ou Terraform. Se você precisa redeployar sua infraestrutura em outra região durante um desastre, o erro humano é seu maior inimigo. Sem IaC, este modelo é apenas um “PowerPoint otimista”.
2. Pilot Light vs. Warm Standby: A sutil diferença
Muitos confundem esses dois modelos. A regra de ouro é:
- Pilot Light: O banco de dados está ligado e replicando (Aurora Global Database), mas o “compute” (EC2/ECS) está desligado ou sequer provisionado.
- Warm Standby: O compute já está lá, rodando em “marcha lenta” (ex: 1 instância mínima no Auto Scaling), pronta para assumir o tráfego instantaneamente.
3. Multi-Site Active/Active: O desafio da escrita global
Para sistemas críticos de alto volume, o tráfego é servido por múltiplas regiões simultaneamente. O principal desafio técnico neste modelo é a consistência de dados entre regiões. Tecnologias como DynamoDB Global Tables (com Last Writer Wins) ou Aurora Write Forwarding são essenciais para evitar conflitos de escrita entre continentes.
O Segredo da Resiliência: Data Plane vs. Control Plane
Um ponto vital da arquitetura AWS: para um failover de sucesso, sua estratégia deve depender do Data Plane.
- Control Plane: Operações de criação/configuração (ex: criar uma nova instância). Em um desastre regional, o plano de controle pode ficar instável.
- Data Plane: Operações de execução (ex: Route 53 respondendo a uma consulta DNS).
Dica de Arquiteto: Prefira estratégias que apenas “viram a chave” no tráfego (Data Plane) em vez de estratégias que dependem de criar recursos do zero durante a crise.
Validando com AWS Resilience Hub
Não basta projetar é preciso testar. Ferramentas como o AWS Resilience Hub permitem definir, rastrear e validar a resiliência dos workloads. Ele analisa sua aplicação e avisa se você realmente conseguirá atingir os alvos de RTO e RPO definidos pelo negócio.
Conclusão: Qual escolher?
Disaster Recovery é uma decisão de negócio executada pela engenharia. Se o seu plano de DR nunca foi testado via simulação de falha, você não tem um plano, apenas uma intenção. Utilize ferramentas de automação e foque no Data Plane para garantir que, quando o desastre vier, sua única ação seja apertar um botão.
- Sistemas de suporte? Backup and Restore.
- Core business que tolera 30 min de queda? Pilot Light ou Warm Standby.
- Missão crítica (pagamentos/saúde)? Multi-Site Active/Active.
Lembre-se: Um plano de DR que nunca foi testado é apenas um “PowerPoint otimista”. Use o AWS Resilience Hub para validar se você realmente entrega o RTO/RPO que prometeu ao seu cliente.
Acompanhe nosso blog para mais conteúdos técnicos e estratégicos sobre AWS e transformação digital.
Referências: