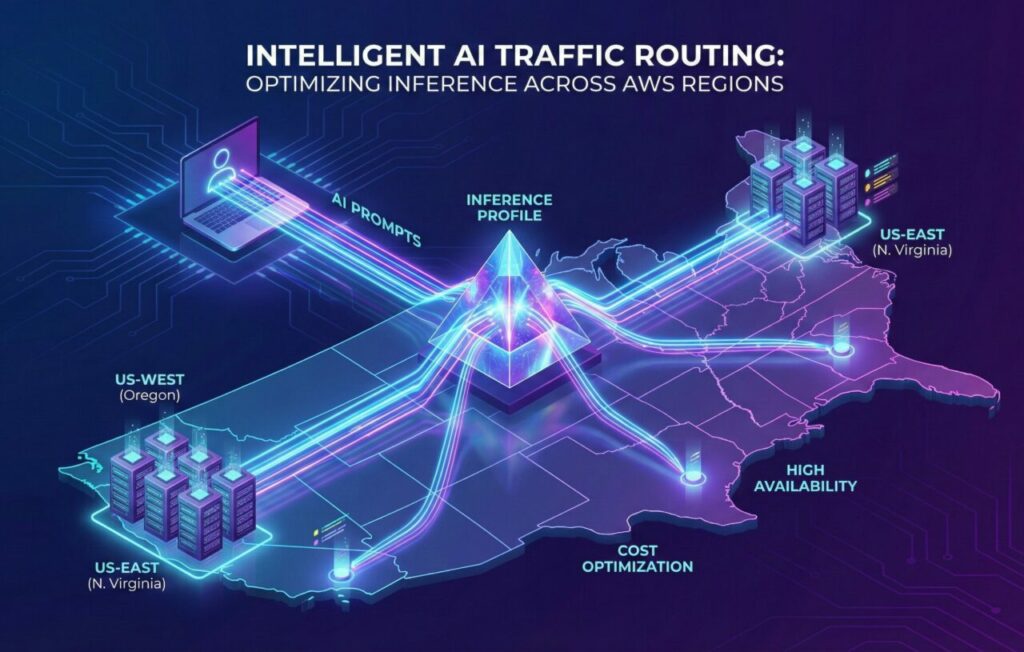
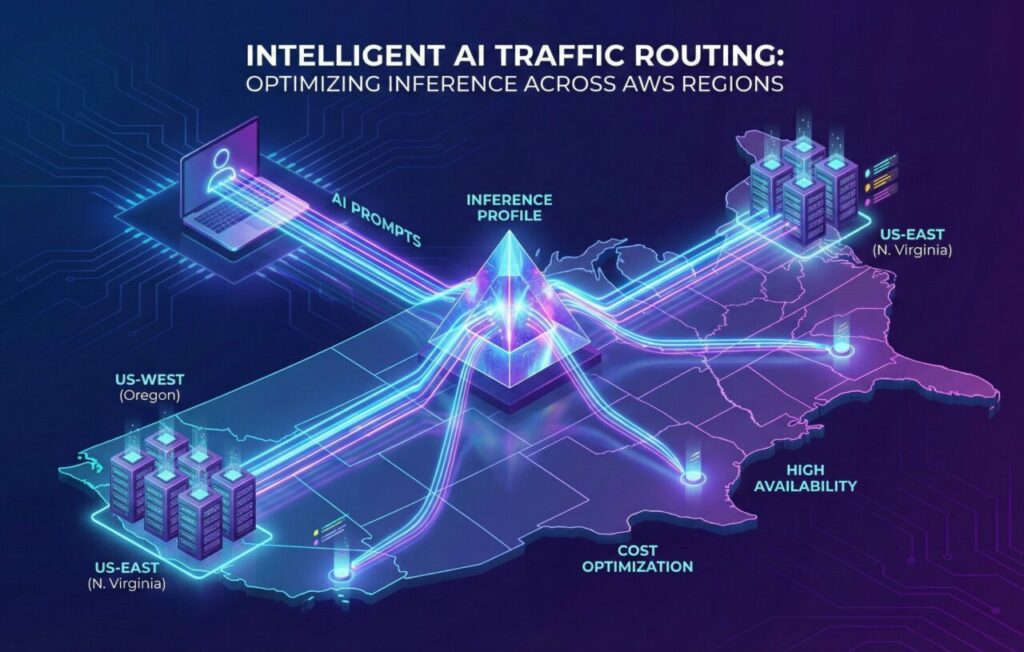
Amazon Bedrock Inference Profiles Como a nova gestão de tráfego de inferência permite failover automático e uso otimizado de instâncias para LLMs em produção.
A explosão da IA Generativa (GenAI) em ambientes corporativos trouxe um desafio inédito para a engenharia de confiabilidade (SRE): como garantir a disponibilidade de LLMs que não controlamos? Diferente de uma base de dados que gerenciamos em EC2 ou RDS, quando usamos modelos fundacionais (FMs) como serviço — seja o Claude 4.5 da Anthropic, o Llama 3 da Meta ou a família Amazon Titan —, estamos sujeitos a quotas de taxa (Rate Limits) e possíveis degradações de serviço regionais.
Até recentemente, a solução era escrever código complexo de “retry” e “fallback” na camada da aplicação, tentando chamar uma região alternativa (ex: us-east-1 falhou, tenta us-west-2) manualmente. Isso adicionava latência e complexidade de manutenção. Com a introdução e maturação dos Amazon Bedrock Inference Profiles, a AWS moveu essa lógica para a camada de infraestrutura. Neste artigo, exploramos como essa abstração muda o jogo para aplicações críticas de GenAI em 2026.
O Problema da Escala e os “Throttling Errors”
Quem já colocou um chatbot em produção sabe: o erro ThrottlingException é o inimigo número 1. Modelos de IA são recursos computacionalmente intensos e finitos. Mesmo com quotas aumentadas, picos de tráfego podem saturar a capacidade de uma região específica. Tradicionalmente, a arquitetura resiliente exigia que você implantasse sua lógica em múltiplas regiões. No entanto, gerenciar endpoints regionais diferentes para o Bedrock significava duplicar configurações e criar uma lógica de roteamento personalizada. Isso não é apenas ineficiente; é propenso a erros humanos durante incidentes.
Inference Profiles: A Abstração Inteligente
Os Inference Profiles funcionam como um balanceador de carga global para modelos de IA. Em vez de invocar um modelo específico em uma região específica (ex: anthropic.claude-3-sonnet-20240229-v1:0 em us-east-1), você invoca um ID de perfil (ex: us.anthropic.claude-3-5-sonnet-20240620-v1:0). O que acontece por trás das cortinas?
- Roteamento Cross-Region: A AWS roteia dinamicamente a requisição para qualquer região definida no perfil (ex: N. Virginia, Oregon, Ohio) que tenha capacidade disponível.
- Transparência: Para a sua aplicação (Lambda, EC2 ou Container), é uma única chamada de API. A complexidade geográfica desaparece.
- Resiliência Nativa: Se
us-east-1sofrer uma degradação de performance ou esgotar a capacidade de GPUs, o tráfego é desviado automaticamente paraus-west-2sem que sua aplicação receba um erro 500 ou 429.
Impacto nos Custos e Operações (FinOps & MLOps)
Um benefício menos óbvio, mas crítico para 2026, é a rastreabilidade de custos. Antes, monitorar o gasto de IA por equipe era difícil porque todos usavam o mesmo modelo base. Com os Application Inference Profiles, você pode criar perfis distintos para “Marketing”, “Engenharia” e “Suporte”, mesmo que todos usem o mesmo modelo Claude 3.5 subjacente.
- Tagging Granular: Cada perfil pode receber tags de alocação de custo. No AWS Cost Explorer, você vê exatamente quanto o chatbot do RH gastou versus o assistente de código dos desenvolvedores.
- Métricas Dedicadas: No CloudWatch, você ganha métricas de latência e erros separadas por perfil. Isso permite identificar se o prompt do time de Marketing está gerando latências mais altas (talvez por falta de otimização) comparado ao time de Engenharia.
Implementação Prática com Terraform/CloudFormation
A configuração de um perfil de inferência cross-region é simples e deve ser o padrão para qualquer ambiente de produção hoje. Exemplo conceitual de definição (IaC):
resource "aws_bedrock_inference_profile" "production_agent" {
name = "Production-Agent-Claude3-5"
description = "Perfil resiliente cross-region para o Agente de Vendas"
model_source {
copy_from = "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0"
}
tags = {
Environment = "Production"
CostCenter = "Sales-101"
}
}
Ao apontar seu código Python (boto3) para este ARN de perfil, você ganha resiliência multi-zona instantânea.Otimização de Latência P99
Testes realizados em Janeiro de 2026 mostram que o uso de perfis cross-region reduziu a latência de cauda (P99) em até 40% durante horários de pico. Por quê? Porque o sistema evita filas de espera em regiões congestionadas. Em vez de esperar 2 segundos para conseguir um slot de GPU na Virgínia, a requisição viaja 60ms até Oregon e é processada imediatamente. O tempo total de resposta é menor, melhorando a experiência do usuário final.
Conclusão
Os Inference Profiles do Amazon Bedrock marcam a maturidade da IA na nuvem. Deixamos a fase de “prototipagem frágil” para entrar na era da “IA resiliente”. Se a sua empresa depende de GenAI para processos críticos, não faz sentido arriscar downtime por congestionamento regional. A migração para perfis de inferência é uma mudança de configuração de baixo esforço com alto retorno em estabilidade e governança.
Essa abordagem faz parte das soluções de automação na AWS oferecidas pela KXC Partner.