Workloads de High Performance Computing (HPC) exigem alto poder computacional, baixa latência e escalabilidade dinâmica. Em ambientes on-premises, isso normalmente significa clusters superdimensionados para picos de demanda.
Na AWS, é possível adotar um modelo elástico utilizando o:
AWS ParallelCluster
Neste artigo, veremos:
- O que é o AWS ParallelCluster
- Como funciona o autoscaling baseado em fila
- Componentes principais da arquitetura HPC
- Quando utilizar essa abordagem
O que é o AWS ParallelCluster?
O AWS ParallelCluster é uma ferramenta open source suportada pela AWS para criação e gerenciamento de clusters HPC na nuvem.
Ele automatiza a implantação de:
- Head Node
- Compute Nodes
- Scheduler
- Storage de alto desempenho
- Configuração de rede otimizada
É ideal para workloads como:
- Simulações científicas
- Modelagem financeira
- CFD
- Genômica
- Processamento distribuído via MPI
Arquitetura de um Cluster HPC Tradicional
Um cluster típico provisionado com ParallelCluster inclui:
- Head Node – Gerencia o cluster e o scheduler
- Compute Nodes – Executam os jobs
- Scheduler – Geralmente Slurm
- Storage compartilhado como Amazon FSx for Lustre
- Instâncias de alto desempenho via Amazon EC2
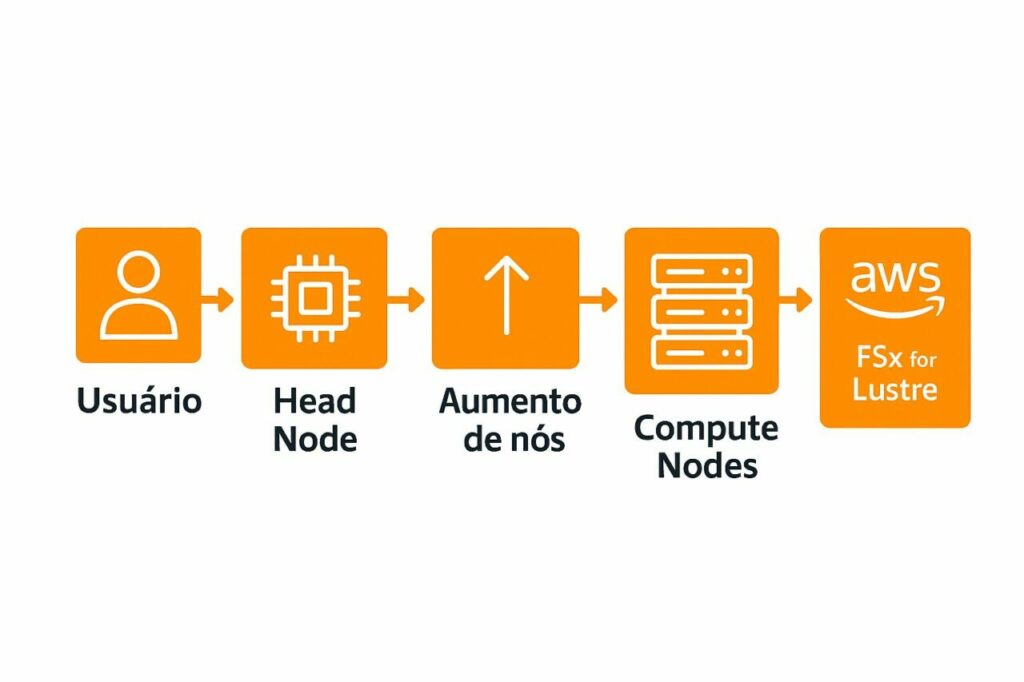
Como funciona o Autoscaling no HPC?
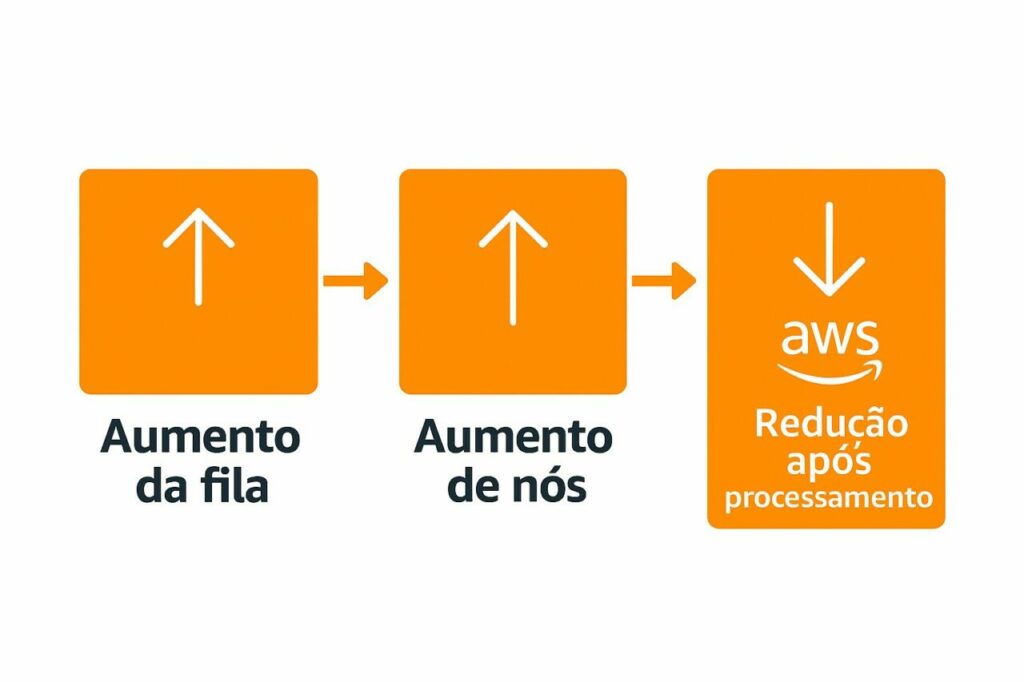
O grande diferencial está no escalonamento baseado na fila do scheduler.
Fluxo típico:
- Usuário submete um job via Slurm
- O job entra na fila
- Se não houver capacidade suficiente:
- Novos Compute Nodes são criados automaticamente
- Quando a fila esvazia:
- Instâncias são desligadas
Isso permite:
- Escalar de 0 a centenas de nós
- Pagar apenas pelo uso
- Evitar superdimensionamento permanente
Instâncias HPC e Alta Performance
O ParallelCluster permite utilizar:
- Instâncias HPC otimizadas
- Placement Groups
- Elastic Fabric Adapter (EFA) para baixa latência
Esse modelo é fundamental para workloads MPI distribuídos, onde a comunicação entre nós é crítica.
Exemplo Conceitual de Configuração
Um arquivo de configuração simplificado inclui:
- Tipo de instância do Head Node
- Tipo de instância dos Compute Nodes
- Número máximo de nós
- Integração com FSx for Lustre
- Configuração do scheduler
O ParallelCluster cuida automaticamente de:
- Provisionamento
- Integração de rede
- Configuração do Slurm
- Política de escalabilidade
Vantagens do AWS ParallelCluster
✅ Provisionamento rápido de cluster HPC
✅ Autoscaling baseado em fila real
✅ Integração nativa com serviços AWS
✅ Suporte a EFA
✅ Modelo pay-per-use
✅ Eliminação de infraestrutura ociosa
Quando utilizar AWS ParallelCluster?
Essa abordagem é ideal quando:
- O workload é baseado em MPI
- Existe necessidade de baixa latência entre nós
- O processamento ocorre em ondas (picos de demanda)
- O ambiente precisa ser temporário (clusters efêmeros)
Para workloads containerizados modernos, outras abordagens como Kubernetes podem ser consideradas. Mas para HPC tradicional com scheduler clássico, o AWS ParallelCluster é a solução mais alinhada.
Conclusão
O AWS ParallelCluster permite transformar um cluster HPC tradicional em uma infraestrutura elástica, escalável e sob demanda.
Com autoscaling baseado na fila do Slurm, integração com Amazon FSx for Lustre e instâncias de alto desempenho no Amazon EC2, é possível executar workloads massivos pagando apenas pelo que for realmente utilizado.
Para organizações que buscam migrar HPC on-premises para a nuvem mantendo performance e controle, essa é uma das arquiteturas mais sólidas disponíveis na AWS.