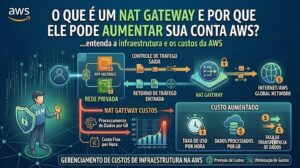
No mundo da computação em nuvem, existe uma frase célebre de Werner Vogels, CTO da Amazon: “Everything fails, all the time” (Tudo falha, o tempo todo). Se você desenha ou gerencia uma infraestrutura assumindo que um servidor, um link de rede ou até mesmo uma Zona de Disponibilidade (AZ) inteira nunca vai cair, sua arquitetura já nasce vulnerável.
Muitas empresas acreditam que o simples fato de “estar na AWS” garante 99.99% de disponibilidade de forma mágica. A realidade é dura: a AWS entrega a infraestrutura resiliente, mas a responsabilidade de desenhar uma aplicação tolerante a falhas é do seu time.
Na KXC Partner, estruturamos soluções baseadas no princípio de Design for Failure (Desenhar para a Falha). Se um componente cair, o sistema precisa se auto-recuperar sem causar impacto no negócio do cliente.
O Ponto de Partida: Definindo as Métricas de Negócio (RTO e RPO)
Antes de abrir o console da AWS ou escrever uma linha de Terraform para criar redundâncias, a engenharia precisa alinhar-se com o negócio para definir duas métricas críticas de Disaster Recovery (DR):
- RPO (Recovery Point Objective – Objetivo de Ponto de Recuperação): Refere-se à quantidade de dados que a empresa aceita perder em caso de desastre. Mede-se em tempo. Se o seu último backup foi há 24 horas e o sistema cai, seu RPO real é de 24 horas.
- RTO (Recovery Time Objective – Objetivo de Tempo de Recuperação): É o tempo máximo que o sistema pode ficar fora do ar até ser totalmente restabelecido. Quanto tempo sua operação aguenta ficar parada sem faturar?
[Momento do Desastre]
│
├─── Retrospectivo: Quanto dado foi perdido? ──> (RPO)
└─── Prospectivo: Quanto tempo até voltar? ──> (RTO)
Reduzir o RTO e o RPO para perto de zero é tecnicamente possível, mas exige investimentos altos. O papel de uma arquitetura eficiente é encontrar o equilíbrio ideal entre o custo da redundância e o impacto financeiro da indisponibilidade.
Estratégias de Resiliência: Do Backup à Nuvem Multi-Região
Dependendo do RTO e RPO definidos, existem quatro estratégias principais para implementar um plano de Disaster Recovery na AWS:
1. Backup & Restore (Abordagem Tradicional)
A forma mais simples e barata. Os dados e snapshots de infraestrutura (como volumes EBS e bancos de dados RDS) são gerados periodicamente e armazenados de forma segura (como no Amazon S3). Em caso de falha grave, a infraestrutura é recriada do zero a partir do código (IaC) e os dados são restaurados.
- Ideal para: Workloads de baixa criticidade ou ferramentas internas.
- RTO/RPO: Horas.
2. Pilot Light (A “Luz Piloto”)
Os dados críticos (como bancos de dados) são replicados em tempo real para outra região ou ambiente, mas a camada de computação (servidores e containers) fica desligada ou configurada em uma escala mínima. Em caso de desastre, essa computação é ligada e escalada rapidamente através de automação.
- Ideal para: Sistemas core que toleram alguns minutos de interrupção.
- RTO/RPO: Minutos.
3. Warm Standby (Pronto para Assumir)
Uma versão duplicada, porém reduzida, de toda a sua infraestrutura fica rodando continuamente em outra Zona de Disponibilidade ou Região AWS. Ela já recebe tráfego de forma tímida. Se o ambiente principal falhar, o roteamento de rede (via Amazon Route 53) direciona 100% do tráfego para o ambiente reserva, que escala imediatamente.
- Ideal para: E-commerces, plataformas de pagamento e APIs críticas.
- RTO/RPO: Minutos ou segundos.
4. Multi-Site Ativo-Ativo (Disponibilidade Total)
O nível máximo de engenharia. A aplicação roda simultaneamente em múltiplos locais (Multi-AZ ou Multi-Region), dividindo a carga de trabalho. Se uma região inteira da AWS sofrer uma interrupção massiva, os usuários nem percebem, pois as outras regiões continuam processando as requisições nativamente.
- Ideal para: Sistemas de missão crítica global.
- RTO/RPO: Próximo de zero.
Boas Práticas Indispensáveis para Alta Disponibilidade
Independentemente da estratégia de DR escolhida, sua infraestrutura base em Produção deve seguir regras claras de Alta Disponibilidade no dia a dia:
- Multi-AZ por Padrão: Nunca rode instâncias EC2 isoladas ou bancos de dados RDS Single-AZ em produção. Distribua suas instâncias de containers (Amazon ECS/EKS) por pelo menos 3 Zonas de Disponibilidade diferentes.
- Camadas Stateless (Sem Estado): Seus servidores de aplicação não devem salvar arquivos ou sessões localmente no disco. Use serviços gerenciados como Amazon ElastiCache (Redis) para sessões e Amazon S3 / EFS para arquivos. Isso permite que qualquer servidor seja destruído e recriado pelo Auto Scaling sem quebrar a experiência do usuário.
- Bancos de Dados Resilientes: Utilize o Amazon Aurora com réplicas de leitura distribuídas ou o Amazon DynamoDB Global Tables se a sua aplicação exigir replicação global ativa multi-região de baixíssima latência.
Conclusão: O melhor plano de DR é aquele que é testado
Projetar uma arquitetura de Alta Disponibilidade no papel é fácil. O verdadeiro teste de fogo acontece quando a falha é simulada. Empresas maduras realizam testes periódicos de DR (como engenharia de caos) para garantir que as automações, backups e políticas de failover funcionem exatamente como planejado quando o pior acontecer.
Resiliência não é um gasto; é a apólice de seguro que protege a reputação do seu negócio e a confiança dos seus clientes.
Sua infraestrutura está preparada para enfrentar uma queda?
Na KXC Partner, ajudamos sua empresa a desenhar arquiteturas de alta resiliência, implementar planos de Disaster Recovery automatizados e migrar sistemas legados para estruturas Multi-AZ e Multi-Region altamente seguras.
Ganta a continuidade do seu negócio antes da próxima instabilidade.
Fale com nossos arquitetos especialistas em Alta Disponibilidade