O Dilema do Microserviço Ocioso
No mundo de arquiteturas orientadas a eventos e microserviços, é comum termos processos pequenos que fazem apenas uma coisa: um validador de tokens, um conversor de logs ou um buscador de metadados.
Se você roda cada um desses em um ECS Service separado usando Fargate, você esbarra no “piso” de cobrança da AWS (mínimo de 0.25 vCPU e 0.5 GB RAM). Se o seu serviço usa apenas 0.05 vCPU, você está pagando por um recurso que nunca será usado. A solução? Task Definition Multi-Container.
1. O Conceito de Unidade Lógica vs. Unidade de Implantação
Muitas vezes confundimos “um container = um serviço”. No ECS, a Task é a unidade de implantação.
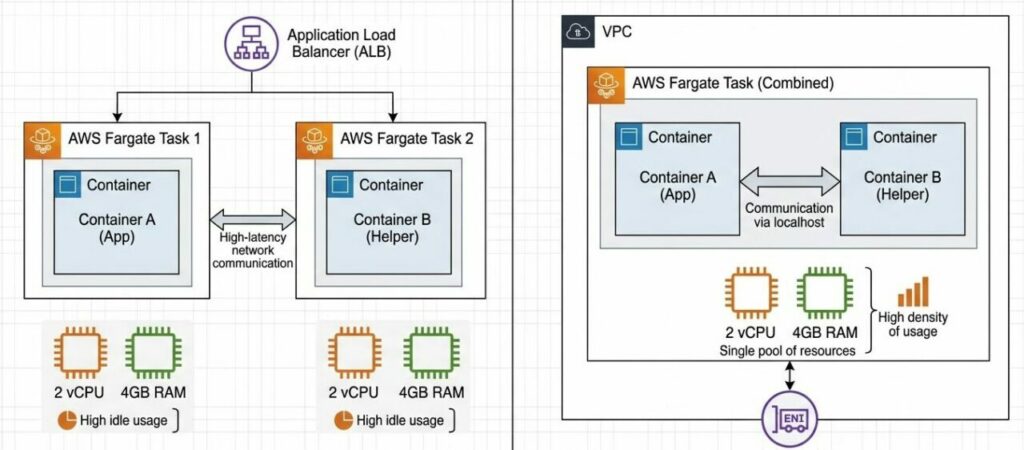
- Single-Container Task: Isolamento total, mas custo mais alto por overhead de rede e infraestrutura.
- Multi-Container Task: Containers compartilham o mesmo “host” lógico, rede (
localhost) e recursos de CPU/Memória.
Quando unir serviços em uma única Task?
- Baixo consumo: Serviços que não justificam uma Task dedicada.
- Alta afinidade: O Serviço A depende inteiramente do Serviço B para funcionar.
- Latência crítica: Quando milissegundos importam e você quer que a comunicação ocorra via
localhostem vez de passar por um Load Balancer (ALB).
2. Anatomia de uma Task de Alta Densidade
Ao colocar dois containers em uma Task, você precisa configurar o compartilhamento de recursos de forma inteligente.
Compartilhamento de Memória (Hard vs. Soft Limits)
No JSON da sua Task Definition, você tem duas formas de limitar a memória por container:
- Memory (Hard Limit): Se o container atingir esse valor, ele sofre um OOM Kill (o container morre).
- Memory Reservation (Soft Limit): O container pode “pegar emprestado” memória ociosa da Task, mas o ECS garante que ele sempre terá pelo menos esse valor disponível.
Dica de Ouro: Use Soft Limits para serviços que têm picos esporádicos, permitindo que eles “roubem” recursos um do outro momentaneamente sem derrubar a Task.
3. Comunicação de Performance: O Fator Localhost
Um dos maiores ganhos de rodar containers juntos é a rede. Ao usar o modo awsvpc (padrão no Fargate), todos os containers da Task compartilham a mesma Interface de Rede Elástica (ENI).
Exemplo Prático: Em vez do seu App chamar o microserviço de autenticação via http://auth.suaempresa.com (passando pelo DNS, Route53 e Load Balancer), ele chama via http://localhost:8081.
- Custo zero de transferência de dados (Data Transfer).
- Latência quase nula.
4. O Cálculo do ROI (Retorno sobre Investimento)
Imagine o cenário real:
- Cenário A (Isolado): 2 Serviços = 2 Fargate Tasks (0.25 vCPU cada) = 0.50 vCPU cobrada.
- Cenário B (Unificado): 1 Task com 2 Containers dividindo os mesmos 0.25 vCPU.
Na prática, você cortou a conta daquele serviço pela metade, mantendo a mesma capacidade de entrega. Para uma empresa com centenas de microserviços, isso representa milhares de dólares ao final do mês.
5. Cuidados e Trade-offs
Nem tudo são flores. Você deve avisar seu leitor sobre:
- Escalabilidade Acoplada: Se você precisar escalar o Container A, o B também será escalado (pois a unidade de escala é a Task).
- Blast Radius: Se um container causar um erro crítico no Kernel ou consumir toda a CPU da Task, o “vizinho” sofrerá as consequências.
- Logs Misturados: É fundamental usar prefixos claros no CloudWatch Logs para não confundir qual container gerou qual erro.
Conclusão
Mudar um serviço pequeno para rodar como um container secundário (sidecar) em um serviço maior não é “gambiarra”, é Engenharia de Custos. É entender que a nuvem é um recurso finito e que a eficiência operacional é tão importante quanto o código limpo.